この記事は Aizu Advent Calendar の 20 日目の記事です。
前日は id:nktafuse の 、
明日は id:ywkw1717 です。
きっかけ
最近職場で Clean Architecture を取り入れたアプリケーションを Python で書いていて、Go でも書けないか?という試みではじめました。
作ったものは、サーバにアップロードしたファイル自体の改竄を検出できる簡易ファイルアップローダみたいなものです。
以下では CA について簡単に解説した後、設計・実装する上で悩んだ点などを挙げています。
Clean Architecture
原文と翻訳版は以下。
クリーンアーキテクチャ(The Clean Architecture翻訳) | blog.tai2.net
注意書き
ここでの CA の説明はあくまで自分が記事を読んで自分なりに解釈したものです。
ソースとは異なる部分もあるかもしれないので注意してください。
概要
CA は上下のあるレイヤードアーキテクチャ等とは異なり、円になっています。
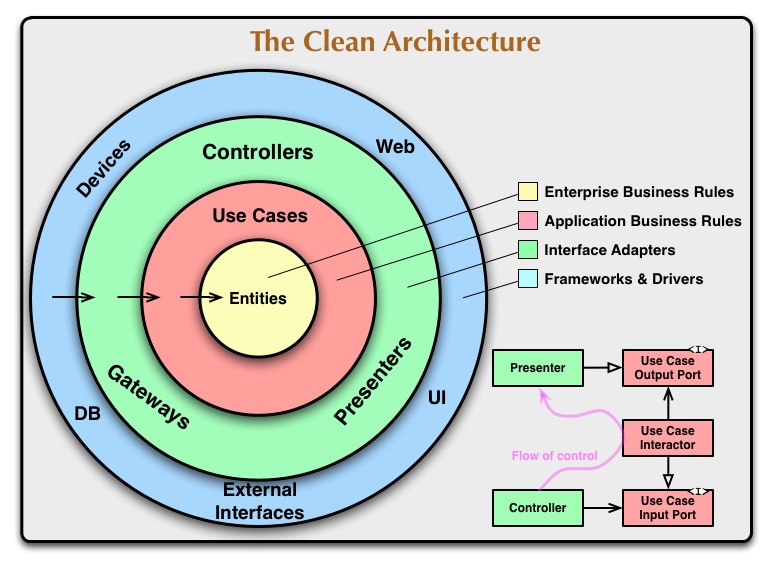
各レイヤーは内側のレイヤーにのみ依存を持つことができ、外側に依存することはできません。
したがって、中央のエンティティ層はいかなるレイヤーにも依存できません。
「依存」という言葉は「使う」という言葉にほぼ同義で置き換えられると思います。
この依存ルールを守ることで、以下のような恩恵が得られます。
原文で上げているいくつかのメリットに自分なりの意見を入れています。
- フレームワーク独立 - フレームワークに引っ張られることを防止し、ビジネスロジックが壊されるのを防ぎつつ、効果的にフレームワークを使える
- テスタビリティの向上 - 各レイヤーが疎結合になることで容易にテストができる
- UI 独立 - UI にビジネスロジックが引っ張られることを防止し、容易に UI を入れ替えることができる
- データベース独立 - MySQL、PostgreSQL の様な各 DBMS の実装に引っ張られることがなくなる
原文の 5 番目で言及しているとおり、上記の全ては一つの仕組みによって実現されています。
以降の説明で紹介していきます。
エンティティ層
エンティティ層は中央の層で、他のどの層にも依存しません。
このレイヤーには各アプリケーションに依存しないビジネスロジックが属します。
一見何を言っているのかわかりませんが、実際の例で説明します。
ユースケース層
エンティティにのみ依存するレイヤーです。
ユースケース層は他のアーキテクチャ等ではアプリケーション層と呼ばれるように、アプリケーション固有のビジネスロジックが入ります。
アダプタ層
原文だとインターフェースアダプターと呼ばれていますが、ちょっと長いのでアダプタ層と略します。
ユースケース層・エンティティ層で使用するデータフォーマットから外部のシステムが使うフォーマットへの変換を担う層です。
ここでは、「外部システム」という言葉が出てきているとおり、各システムの実装が初めて出てきます。
例えば、エンティティから何かしらのデータが渡されて、それを SQL を使っている RDBMS へ保存するというケースを考えてみましょう。
RDBMS で「保存する」と言うのは、つまり永続化のことです。 (これはドメインの仕様によりますがほぼ永続化のことでしょう)
つまり、アダプタ層で行うことというのは、エンティティから返されたデータを加工して、INSERT や UPDATE などの SQL 文を発行するということを指しています。
アプリケーション層やエンティティ層はこれを知るよしもありません。アダプタ層はそれらより外側のレイヤーなので依存できないからです。
ドライバ層
原文だとフレームワーク & ドライバ層と呼ばれています。
SQL DB の場合、Go だと既に database/sql で抽象化されていて、かつ入力も Web Request でしか受け付けないことが前提なので、今回はドライバ層とアダプタ層を一括りにして扱っています。
DIP、DI
各レイヤーをまたがる場合を考えます。
例えば、Web サーバアプリケーションを作っている場合、その controller はアダプタ層に存在します。
リクエストが来た場合、それをアダプタ層の controller が受け取ってユースケース層のメソッドを呼び出します。
ユースケースは、その処理の終わりに結果を返さなければいけませんが、外側に干渉するような操作は依存することになるのでできません。
そこで、DIP を使ってこれを解決します。
DIP は Dependency Inverse Principal の略で、日本語だと「依存関係逆転の原則」などと呼ばれます。
本来依存する側 (今回はユースケース層) がインターフェースを定義し、それを外側の層が実装します。
これは、インターフェースという抽象型に依存しているので、 「抽象に依存する」 と言います。
レイヤー間を抽象に依存するようにしてあげると、疎結合なソフトウェアを構築することができます。
ユースケースはただ自分が定義したインターフェースを満たした実装を利用することができるようになるので、依存関係を逆転させることができます。
上で説明したとおり、アダプタ層で実装を与え、それをユースケース層・エンティティ層が使うために、何らかの方法で実装を渡さなければいけません。
このために DI を使います。DI は Dependency Injection の略で、「依存性の注入」などとよく呼ばれています。もっとも簡単な方法として、引数の型をインターフェースにし、その関数へインターフェースを満たしている実装を渡してあげる方法があり、今回もこれを利用しています。
type Greeter interface { Hello() } type English struct {} func (e *English) Hello() { fmt.Println("Hello") } type Japanese struct {} func (j *Japanese) Hello() { fmt.Println("こんにちは") } func doHello(greeter Greeter) { greeter.Hello() } func main() { doHello(&English{}) // "Hello" doHello(&Japanese{}) // "こんにちは }
ただの部分型付けポリモーフィズムですね。
実際に適用する
再掲
github.com
ただ、全部を書くと膨大になるので、一部だけ紹介しています。
アプリケーションのシーケンス図は以下の様になっています 👇

エンティティ層
このアプリケーションではエンティティ層は domain という名前のパッケージが相当します。
小さなアプリケーションなので、エンティティは file.go に定義されている File 型しかありません。
また、そのエンティティの永続化を行うリポジトリ、FileRepository が定義されています。
ここで注目してほしいのが、 FileRepository は interface で定義されている点です。つまり、実装はエンティティ層には存在していません。実装は、CA での説明でも触れたとおり、アダプタ層にあります。
ユースケース層
ユースケース層に相当するパッケージは、usecases パッケージです。
usecases/ports には、ユースケースが必要とする port を定義しています。
具体的には、 BlockchainPort 、CryptoPort や StoragePort があります。
また、InputPort / OutputPort が server.go に定義されています。
これは、上で紹介した図の右下の図に書いてあり、サーバへの input とそのレスポンスに相当する output を DIP でどう表現するか?が原文で説明されています。
この図から分かる通り、I/O port はユースケース層で定義され、input port の実装は interactor です。
また、input port に controller が依存しています。
同じように、output port の実装はアダプタ層の presenter で、今度は interactor が output port に依存しています。
interactor は、各ユースケースに DI をする役割を担っています。
interactor のコンストラクタが呼ばれる時に、port の実装である adapter をすべて受け取ります。しかし、ユースケース層は adapter のことを知らない (知ってはいけない) ため、抽象型で受け取ります。
アダプタ層
アダプタ層に相当するパッケージは adapters と presenters です。
二つのパッケージに分けるかどうかは完全に好みです。
presenters は、上のセクションで触れたとおり、output port インターフェースを満たした実装が入っています。
adapters も、各 port の実装が入っています。
ここで注目すべきは、 port のインターフェースを満たしていれば、あらゆる adapter を自由に渡せることです。
例えば、 adapters/repositories には FileRepositoryPort を実装した MockFileRepository がありますが、これは後から MySQLFileRepository などのように、RDBMS をバックエンドにしたものを作り、interactor へこれを渡すようにすれば、アダプタ層より下のレイヤーに全く影響を与えずに実装を入れ替えることができます。
テスト
各レイヤーが疎結合になっているため、簡単にテストを書くことができます。
例えば、 usecases/usecases_test.go を見てみると、repository や storage などの port で定義されている外部パーツは、port を満たすダミー実装に置き換えていることが分かるかと思います。
このように、外部依存に苦しまずにアプリケーションロジックにのみ集中してテストを書くことができます。
まとめ
ざっとですが、Clean Architecture の説明とその実装を紹介しました。
Clean Architecture は、外部システムの仕様変更が予期される場合に対して非常に強固にアプリケーション以下のレイヤーを保護してくれます。
ファイル数は比較的多くなってしまいますが、しっかりとレイヤーを分けられることと比べれば、デメリットとしては小さいのではないかと思っています。
もし、なにか根本的に間違っているようなことがあれば、指摘頂けると助かります 🙇♂️